
Rencontrez le Chat : Introduction rapide à PURR DATA (vs Pd-l2ork vs Pd-extended vs Pure Data)

Tout ce que vous avez toujours voulu savoir sur PURR DATA (données ronronnantes) sans jamais oser le demander à votre matou préféré ! 😉
• Mise à jour : Septembre 2020
Cet article est la traduction aussi fidèle que possible de :
- Meet the Cat: A Quick Introduction to Purr Data – Mise à jour de septembre 2020
écrit par le Docteur Albert Gräf du Département de Musique Informatique – Institut de Musicologie et Histoire de l’Art @ l’Université Johannes Gutenberg (JGU) à Mayence en Rhénanie-Palatinat, Allemagne.- Illustration en Video – Getting Started with Purr Data by Albert Gräf (Graef) – durée 1h31 en anglais
Présentation donnée durant la LAC 2018 (Linux Audio Conference) en juin 2018 à Berlin
- Illustration en Video – Getting Started with Purr Data by Albert Gräf (Graef) – durée 1h31 en anglais
- Site personnel d’Albert Gräf (sur GitHub) — Vous y découvrirez de nombreux utilitaires très intéressants dans les domaines de la musique et du multimédia sur ordinateur.
Purr Data, aussi connu comme Pd-l2ork v.2, est une version améliorée du logiciel libre interactif de musique assistée par ordinateur et multimédia Pure Data (Pd) de Miller Puckette. Purr Data fonctionne au moins sous les systèmes d’exploitation libres GNU/Linux (Arch, Debian, Fedora, openSUSE, Ubuntu, et toutes leurs dérivées comme Manjaro, Linux Mint, etc.), et propriétaires macOS et Windows, et son interface graphique utilisateur est disponible (actuellement) en 3 langues : allemand, anglais (défaut) et français.
Cet article fournit aux nouveaux et potentiels utilisateurs de Purr Data une introduction en douceur au programme et quelques informations utiles pour commencer à programmer des patches (modules) avec les centaines d’objets graphiques internes et externes (bibliothèques) disponibles.
Pour compléter cet article, vous pouvez aussi consulter
- Présentation de Purr Data (Pd-l2ork) – Programmation graphique orientée objet – 10/07/2019
- Introduction à la programmation MIDI avec Pure Data – 29/06/2019
◊ Au sommaire
- C’est quoi Purr Data ?
- Le nom Purr Data ?
- Obtenir Purr Data ?
- Démarrer avec Purr Data
- Configuration de Purr Data
- Obtenir de l’Aide
- Friandises Pd-l2ork et Purr Data
- Purr Data et Pd-Lua
- Trucs et astuces
♦ C’est quoi Purr Data (Pd-L2Ork v.2) ?
Purr Data est la dernière branche (version 2.x) de Pd-L2Ork du Docteur Ivica Ico Bukvic – Director, Creativity + Innovation @ Virginia Tech aux USA. Pd-l2ork est à son tour une variante (fork) de Pd-extended de Hans-Christoph Steiner, qui a été la variante la plus ancienne (et sans doute la plus populaire) de Pure Data de Miller Puckette. Pure Data (Vanilla) est aussi connu en abrégé comme Pd.
Pure Data, la base commune de toutes ces variantes, est l’environnement graphique interactif de musique assistée par ordinateur (MAO) et multimédia de Miller Puckette. Pd est également la principale alternative libre à code source ouvert au célèbre programme commercial Max de Cycling’74 (dont la version originale a également été développée par Miller Puckette quand il était à l’IRCAM dans les années 1980).
Il existe quelques autres applications populaires et très performantes dans le domaine de la musique par informatique et de l’art du multimédia, notamment Csound et SuperCollider. Mais l’attrait spécial de Max et Pd est que vous travaillez dans un environnement graphique intuitif de ‘patches’ (modules) qui vous permet de créer des applications avancées de traitement du signal en temps réel (Audio & MIDI) sans avoir à apprendre un ‘vrai’ langage (textuel) de programmation.
La version de Puckette du programme est parfois appelée en plaisantant Pd ‘Vanilla’ (vanille), car il est livré sans extras et fournit donc le goût le plus pur de Pd, pourrait-on dire. Conformément à cette métaphore, les autres variantes de Pd sont souvent appelées ‘saveurs’.
Alors que Pd Vanilla, étant l’implémentation de référence, reste d’une importance cruciale pour le développement du moteur temps réel de Pd, son interface utilisateur graphique basée sur Tcl/Tk n’a jamais été très jolie ni pratique. Par conséquent, la communauté a tenté à plusieurs reprises d’améliorer l’interface utilisateur de Pd de diverses manières.
Pd-extended fût l’un des premiers et est le plus ancien de ceux-ci, qui comprend également une sélection assez complète de modules complémentaires tiers (‘externals’ / librairies externes d’objets). Cependant, son développement s’est arrêté en 2013 en raison du manque de contributions, et donc il ne reçoit plus de corrections de bogues ni de mises à jour du moteur temps réel.
Ico Bukvic a présenté Pd-l2ork en 2010 en tant que fork de Pd-extended destiné à être utilisé par le Linux Laptop Orchestra (L2Ork) qu’il a fondé à la School of Performing Arts de Virginia Tech (Blacksburg, Virginia, USA).
Bien que la motivation initiale était de créer une version améliorée de Pd-extended à être utilisée par le L2Ork (d’où le nom) ainsi que dans l’éducation, sous GNU/Linux, il est rapidement devenu une alternative plus à jour de Pd-extended offrant un bon nombre de corrections supplémentaires de bogues et d’améliorations de l’interface graphique. Cela est principalement dû à son modèle de développement plus agile qui permet une mise en œuvre plus rapide des corrections de bogues et des améliorations même si cela peut avoir un impact sur la compatibilité descendante.
Pd Vanilla, en revanche, a nécessairement une vision beaucoup plus ferme de la rétro-compatibilité, de sorte qu’il est toujours en mesure d’exécuter de très anciens patches (modules) créés avec d’anciennes versions de Pd.
Malgré les nombreuses et substantielles améliorations qu’elle offre, l’interface graphique de Pd-l2ork est toujours basée sur Tcl/Tk. Ceci est à la fois bon et mauvais. Le principal avantage est la compatibilité avec Pd Vanilla. D’un autre côté, Tcl/Tk a l’air et se sent dépassé de nos jours, même en allant plus loin avec le thème, comme le fait Pd-l2ork. Tcl est un langage de programmation plutôt basique, et ses bibliothèques ont pris du retard, ce qui rend difficile l’intégration des dernières avancées dans les technologies de l’interface graphique utilisateur (GUI), du multimédia et du web. En outre, l’adoption de Pd-l2ork a été entravée par le fait qu’il était essentiellement lié à GNU/Linux, et qu’une solution multi-plateforme était donc nécessaire.
En 2015, Jonathan Wilkes est intervenu et a commencé à créer Purr Data pour résoudre ces problèmes. En un mot, Purr Data est Pd-l2ork avec la partie GUI Tcl/Tk enlevée et remplacée par la technologie web moderne. À ces fins, il utilise un framework open-source appelé NW.js, aussi connu comme ‘node-webkit’, qui est essentiellement un moteur de navigateur web autonome (Chromium) combiné avec un moteur d’exécution JavaScript (Node.js). Alors que ce dernier a été à l’origine inventé pour développer des applications Web côté serveur, des frameworks comme NW.js permettent aux deux d’être utilisés de concert pour créer des applications de bureau portables à part entière. L’utilisation de NW.js garantit que Purr Data s’exécute aussi bien sur GNU/Linux que macOS et Windows, à l’identique sur toutes les plates-formes prises en charge, et il ouvre la voie à tirer partie des technologies Web standard telles que JavaScript, HTML5, CSS3 et SVG.
L’interface graphique de Purr Data est entièrement écrite en JavaScript, qui est un langage de programmation beaucoup plus avancé que Tcl avec une abondance de bibliothèques et de supports. Cela rend le développement de l’interface graphique utilisateur de Purr Data beaucoup plus facile maintenant que le port du GUI initial est terminé. Les correctifs sont implémentés en tant que documents HTML5 SVG qui offrent une meilleure réactivité et des capacités graphiques que les fenêtres Tk. Ils peuvent également être thématiques à l’aide de CSS et zoomés comme n’importe quelle fenêtre de navigateur, améliorant la convivialité et l’utilisabilité. Purr Data est également plus beau et plus agréable à regarder que Pd-l2ork, sans parler de Pd Vanilla, en particulier sur les écrans à haute résolution (high-dpi).
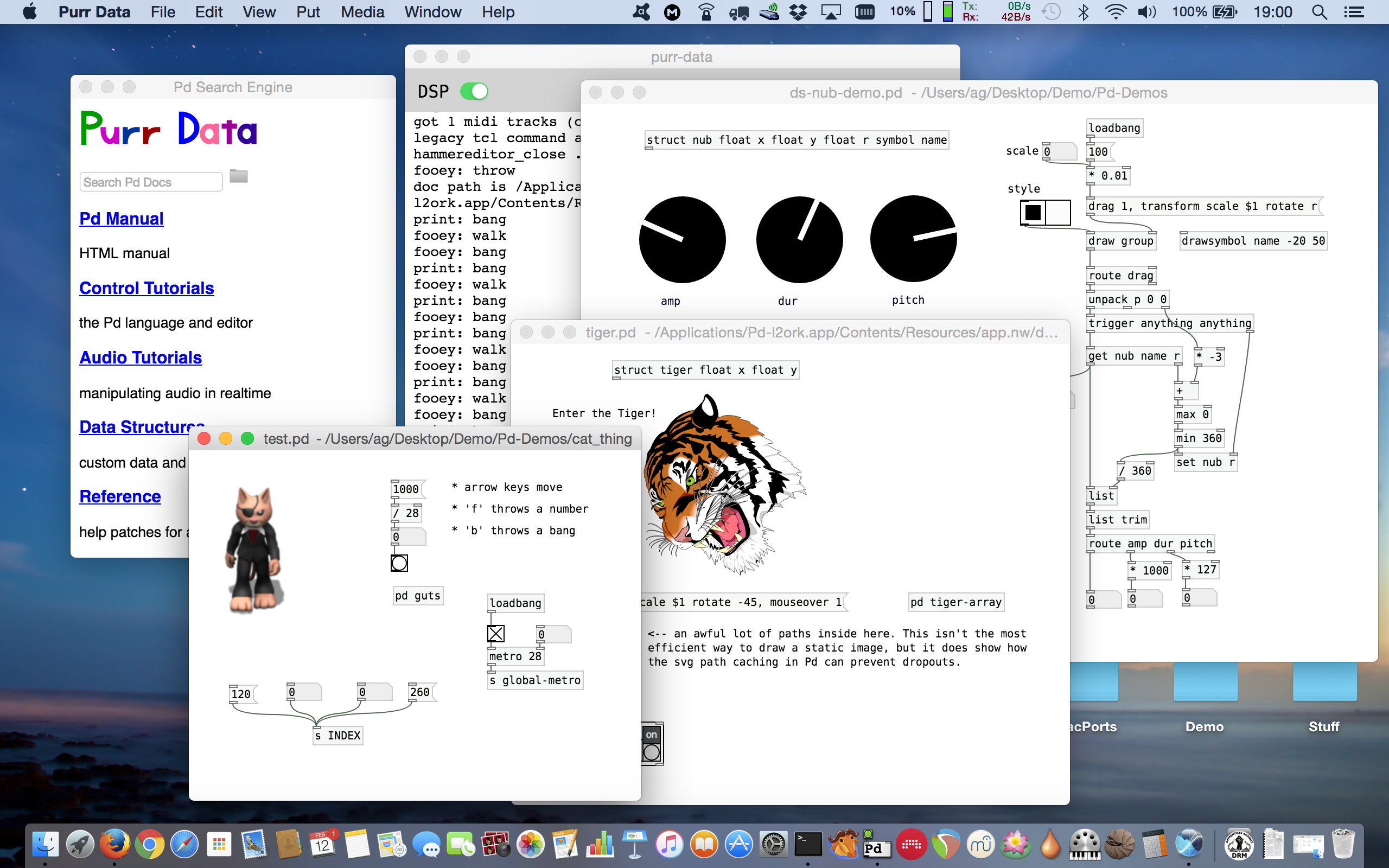
Purr Data tournant sous macOS
L’interface graphique NW.js de Purr Data présente également certains inconvénients.
Tout d’abord, certains des éléments externes inclus dépendent toujours du code Tcl, de sorte que leurs fonctionnalités GUI ne fonctionneront pas dans Purr Data jusqu’à ce qu’elles soient portées vers la nouvelle interface graphique.
Deuxièmement, la taille du paquet binaire est considérablement plus grande qu’avec Pd-l2ork ou Pd-extended car elle inclut également la distribution binaire NW.js complète. (Il s’agit d’une préoccupation valable avec la plupart des soi-disant ‘applications de bureau portables’ proposées ces jours-ci, mais dans le cas de Purr Data, elle est atténuée par le fait que sa base Pd-l2ork n’est pas exactement un package mince non plus.)
Troisièmement, le moteur de navigation Chromium a une empreinte mémoire beaucoup plus élevée que Tcl/Tk, ce qui pourrait être un problème sur les plateformes embarquées avec des contraintes de mémoire de travail très strictes.
Bien qu’aucun de ces problèmes ne doit normalement être un véritable obstacle sur les plateformes prises en charge, il convient de les garder à l’esprit.
Enfin, Purr Data est encore relativement jeune, mais avec sa base éprouvée Pd-l2ork, la présente version a été minutieusement testée et de nombreux bogues ont été corrigés, de sorte qu’elle est certainement prête pour une utilisation au quotidien. Elle offre également des avancées vraiment convaincantes par rapport à ses prédécesseurs. Si vous recherchez un successeur moderne et activement maintenu de Pd-extended, c’est Purr Data qu’il vous faut.
♦ Le nom Purr Data ?
Purr Data est le surnom officiel de la branche Pd-l2ork v.2.x. Pour citer son développeur en chef Jonathan Wilkes lors de son annonce initiale sur le forum Pd :
Je l’ai surnommé « Purr Data », en référence aux chats.
De toute évidence, le nom est un jeu sur « Pure Data » sur lequel « Purr Data » est finalement basé. Il soulève également des connotations positives de sons ronronnants (purr) apaisants et crée un joli logo.
Nous appelons également la version originale Pd-l2ork de Bukvic Pd-l2ork 1.0 ou Pd-l2ork ‘classique’. Notez que Purr Data montre toujours clairement son héritage Pd-l2ork. Il partage beaucoup de code avec Pd-l2ork (essentiellement toutes les parties non-GUI), et l’exécutable, le répertoire de la bibliothèque, etc. sont toujours également nommés pd-l2ork.

Données ronronnantes

Purr Data — Walking Cat
♦ Obtenir Purr Data ?
Jonathan Wilkes gère les codes open sources de Purr Data dans GitLab.
Il existe également un miroir de ce référentiel sur GitHub, maintenu par Albert Gräf, qui sert de guichet unique pour la dernière source et les versions disponibles, y compris des paquets prédéfinis pour macOS et Windows. Vous pouvez les trouver ICI. Les derniers packages sont disponibles LÀ.
Les paquets pour macOS et Windows sont autonomes
Le package Windows est distribué sous la forme d’un exécutable d’installation (fichier .exe). Normalement, vous pouvez simplement exécuter ce package en double-cliquant dessus dans votre gestionnaire de fichiers et suivre la procédure d’installation. Si une version précédente est déjà installée, l’installeur vous proposera de le désinstaller d’abord pour vous (recommandé).
Le package Mac est distribué sous forme d’image disque (fichier .dmg); double-cliquer sur l’image disque dans le Finder ouvre une nouvelle fenêtre du Finder, dans laquelle vous pouvez faire glisser l’application vers votre dossier Application.
Les paquets pour les distributions GNU/Linux
À la JGU (Johannes Gutenberg University), nous maintenons une collection de packages GNU/Linux pour Arch Linux (via les Arch User Repositories a.k.a. AUR) et les versions récentes d’openSUSE, Debian, Ubuntu, et leurs dérivées (via OBS a.k.a. Open Build System). L’OBS propose également des packages binaires pour Arch Linux. Vous trouverez plus d’informations et des instructions d’installation sur la page Wiki dédiée du projet. Outre Purr Data, ces référentiels contiennent également le Pd-l2ork ‘classique’. De plus, deux extensions de programmation supplémentaires pour Purr Data sont disponibles qui vous permettent d’exécuter des librairies (externals) : Faust (Functional AUdio STream language) et Pure (Functional programming language) dans Pd-l2ork et Purr Data. Les packages JGU offrent également l’avantage de vous permettre d’installer à la fois Pd-l2ork ‘classique’ et Purr Data sur le même système.
Bien sûr, il est également possible de créer des binaires de Purr Data à partir des codes sources. Avec les derniers ajouts au système de construction, cette tâche est devenue beaucoup moins intimidante qu’auparavant, et le site Web de Purr Data contient quelques instructions. Cependant, en raison du grand nombre de librairies (externals) incluses, le processus de construction est plutôt compliqué, nécessite beaucoup de dépendances tierces et prend un temps certain, même sur du matériel haut de gamme moderne. Par conséquent, à moins que votre système ne soit pas officiellement pris en charge ou que vous ayez des exigences spécifiques vous obligeant à compiler à partir du code source, nous vous recommandons d’utiliser plutôt les binaires disponibles pour votre système d’exploitation.
♦ Démarrer avec Purr Data
Une fois que vous avez installé Purr Data sur votre ordinateur, vous pouvez le lancer comme d’habitude à partir de l’environnement de bureau. Gardez en mémoire qu’à ce jour l’interface utilisateur de cette application n’existe qu’en anglais (default), allemand et français, et que toutes les bibliothèques (externals) sont en anglais.
Sous GNU/Linux, vous pouvez simplement exécuter pd-l2ork à partir de la ligne de commande, ou rechercher dans le menu du système ou le lanceur de votre environnement de bureau l’entrée ‘Pd-L2Ork’ et cliquer dessus. Si vous avez installé Purr Data à partir de l’un des packages JGU, utilisez plutôt la ligne de commande purr-data ou l’icône du bureau ‘Purr-Data’.
Sous macOS et Windows, double-cliquez sur l’icône de l’application, qui se trouve normalement dans le dossier Application sur macOS et sur le bureau sous Windows. Si vous n’avez pas créé d’icône de bureau lors de l’installation de Windows, recherchez ‘Purr-Data’ dans le menu Démarrer.
Vous pouvez également cliquer avec le bouton droit de la souris sur un fichier patch (avec l’extension .pd), choisir ‘Ouvrir avec’, puis sélectionner Pd-L2ork ou Purr Data pour ouvrir le patch (module) dans Purr Data. Cela peut toutefois nécessiter une première configuration pour associer le type de fichier .pd au programme Purr Data. La plupart des environnements de bureau vous permet également de définir Purr Data comme application par défaut pour les fichiers .pd, afin que vous puissiez ensuite ouvrir les fichiers de patch simplement en double-cliquant dessus. Les détails sont spécifiques au système utilisé; généralement un clic droit sur le fichier puis en choisissant ‘Propriétés’ ou une option similaire (‘Obtenir des informations’ sur macOS) vous donnera une boîte de dialogue qui vous permettra de modifier l’association de fichier.
Dans tous les cas, Purr Data devrait alors lancer sa fenêtre principale Console qui enregistre tous les messages du programme. Si vous avez ouvert un fichier patch, il sera affiché dans une fenêtre Canevas distincte.
À gauche : la Console — À droite : About Pd-l2ork / Purr Data
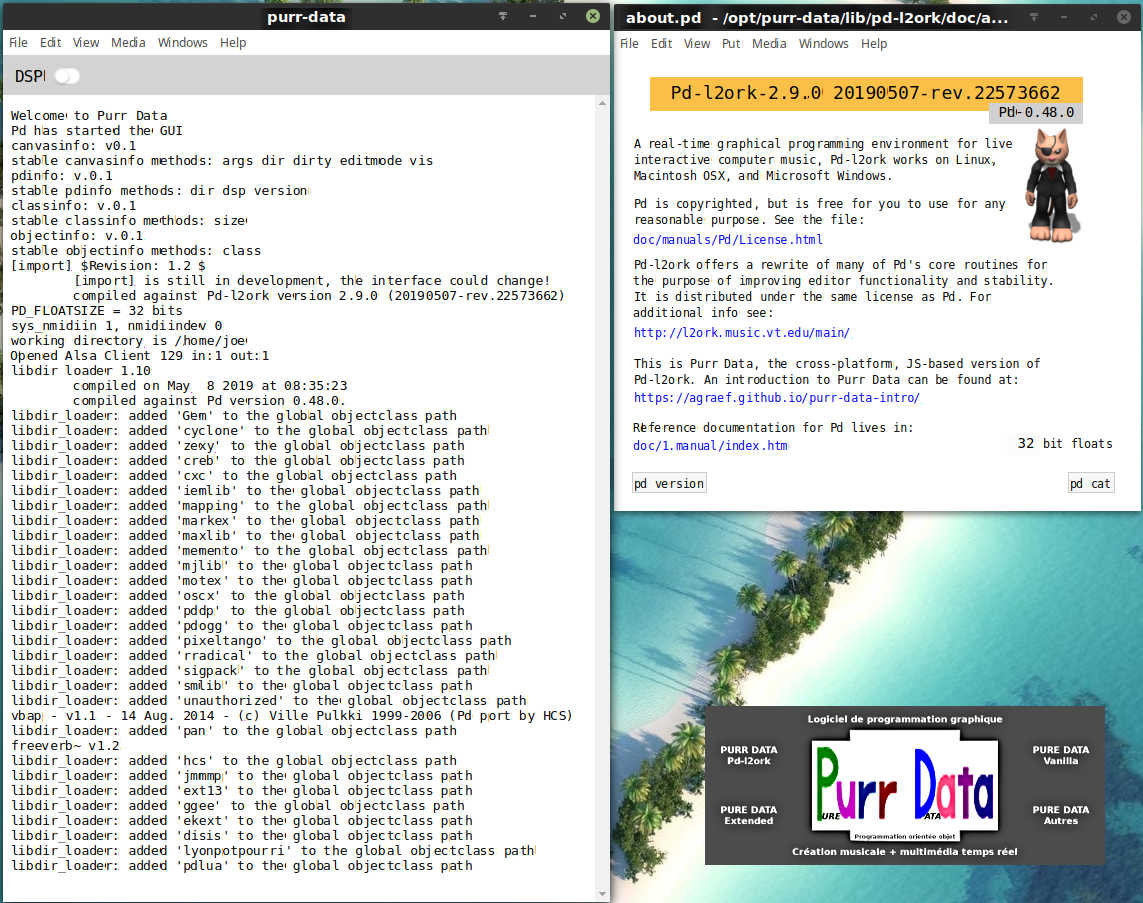
Purr Data (Pd-l2ork v.2) sous GNU/Linux : Vue de la console au 1er lancement du logiciel
| Action | Lance | Ouvre | Puis |
| Purr Data ou Pd-L2Ork | Application | Console | — |
| Fichier .pd | Purr Data | Console | Canevas |
Purr Data comprend essentiellement le même ensemble d’options de ligne de commande que Pd Vanilla ou Pd-l2ork. Sous GNU/Linux, vous pouvez les découvrir en exécutant pd-l2ork -help (purr-data -help lors de l’utilisation des packages JGU) à partir de la ligne de commande. Ce n’est pas facile à faire sur Mac et Windows car l’exécutable du programme est rangé quelque part dans le dossier de l’application. Certaines options courantes qui peuvent être placées dans les Startup flags (indicateurs de démarrage) de Purr Data sont -path et -lib, voir la section GUI et Startup options (Interface graphique et Options de démarrage).
Instance d’application unique
Contrairement à Pd Vanilla, Purr Data s’exécute normalement comme une seule instance d’application. Si vous chargez des fichiers patch supplémentaires (en appelant l’exécutable pd-l2ork ou en cliquant sur les fichiers de patch dans le gestionnaire de fichiers), ils seront ouverts en tant que nouvelles fenêtres de canevas dans cette seule instance unique. Cela évite le type de confusion qui survient souvent avec Pd Vanilla si vous ouvrez accidentellement différents patches dans différentes instances de l’application. Pd Vanilla nécessite que les patches soient chargés dans la même instance du programme s’ils doivent communiquer via le système de messagerie intégré de Pd (send/receive – envoyer/recevoir), ou si vous souhaitez copier/coller des sous-patches entre eux à l’aide du presse-papiers interne. Dans sa configuration par défaut, Purr Data s’assure que c’est toujours le cas.
Instances d’application multiples
Depuis la version 2.3.2, Purr Data peut également être invoqué avec l’indicateur -unique pour créer plusieurs instances d’application. Sous GNU/Linux, vous pouvez le faire en spécifiant simplement l’option -unique sur la ligne de commande ou en modifiant l’icône du bureau que vous utilisez pour lancer Purr Data. Sur Mac et Windows (ainsi que GNU/Linux), vous pouvez placer cette option dans les Startup flags (indicateurs de démarrage) dans les Préférences de Purr Data, voir la section GUI et Startup options (options de démarrage) ci-dessous. N’oubliez pas de supprimer à nouveau l’option des indicateurs de démarrage lorsqu’elle n’est plus nécessaire, afin de revenir au comportement normal d’une instance d’application unique.
Pour la plupart des projets Audio, MIDI et Multimédia, cela ne devrait pas être nécessaire et l’instance d’application unique sera la plus pratique. Mais il existe certaines situations dans lesquelles vous souhaiterez exécuter plusieurs instances de Purr Data à la place. Étant donné que le traitement temps réel de Purr Data se fait sur un seul processus associé à l’instance d’application, une seule instance d’application ne peut pas tirer partie des capacités multi-traitement des systèmes multi-cœurs modernes. Certains cas d’utilisation courants pour le multi-traitement sont si votre projet Purr Data implique à la fois un traitement Audio et graphique (en utilisant généralement la bibliothèque Gem), ou si vous avez plusieurs processus Audio indépendants que vous souhaitez exécuter en parallèle. Dans de tels cas, vous souhaiterez utiliser l’option -unique pour lancer deux ou plusieurs instances de Purr Data, chacune avec ses propres ensembles de patches (modules .pd) qui s’exécuteront ensuite sur différentes instances du moteur temps réel.
♦ Configuration de Purr Data
Lorsque vous lancez Purr Data pour la première fois, vous devrez probablement configurer certaines choses, telles que les périphériques Audio et MIDI que vous souhaitez utiliser. Comme Pd-l2ork, Purr Data fournit une boîte de dialogue centrale Préférences qui vous permet de le faire de manière pratique.
Périphériques Audio et MIDI
La capture d’écran ci-dessous montre à quoi ressemblent les onglets Audio et MIDI de cette boîte de dialogue sur Mac. Dans la plupart des cas, il suffit de sélectionner les entrées et sorties Audio et MIDI que vous souhaitez utiliser dans les listes déroulantes correspondantes. Appuyez sur le bouton Apply pour appliquer les paramètres sans fermer la boîte de dialogue ni enregistrer les options de façon permanente. Si vous souhaitez rendre vos modifications permanentes, vous devez utiliser le bouton OK à la place. Cela ferme également la boîte de dialogue.
Vous pouvez refaire cette procédure à tout moment si nécessaire. Notez qu’il est généralement possible de sélectionner plusieurs périphériques d’entrée et de sortie, mais cela dépend de la plateforme et du back-end Audio/MIDI ou ‘API’ sélectionné. Notez également que sous GNU/Linux (à l’aide de l’API ALSA), l’onglet MIDI vous permettra uniquement de définir le nombre de ports d’entrée/sortie MIDI ALSA à créer; vous devez alors encore utiliser un programme de baie de brassage (patchbay) MIDI tel que QjackCtl (ou Catia ou Patchage) pour connecter ces ports aux périphériques matériels selon vos besoins.
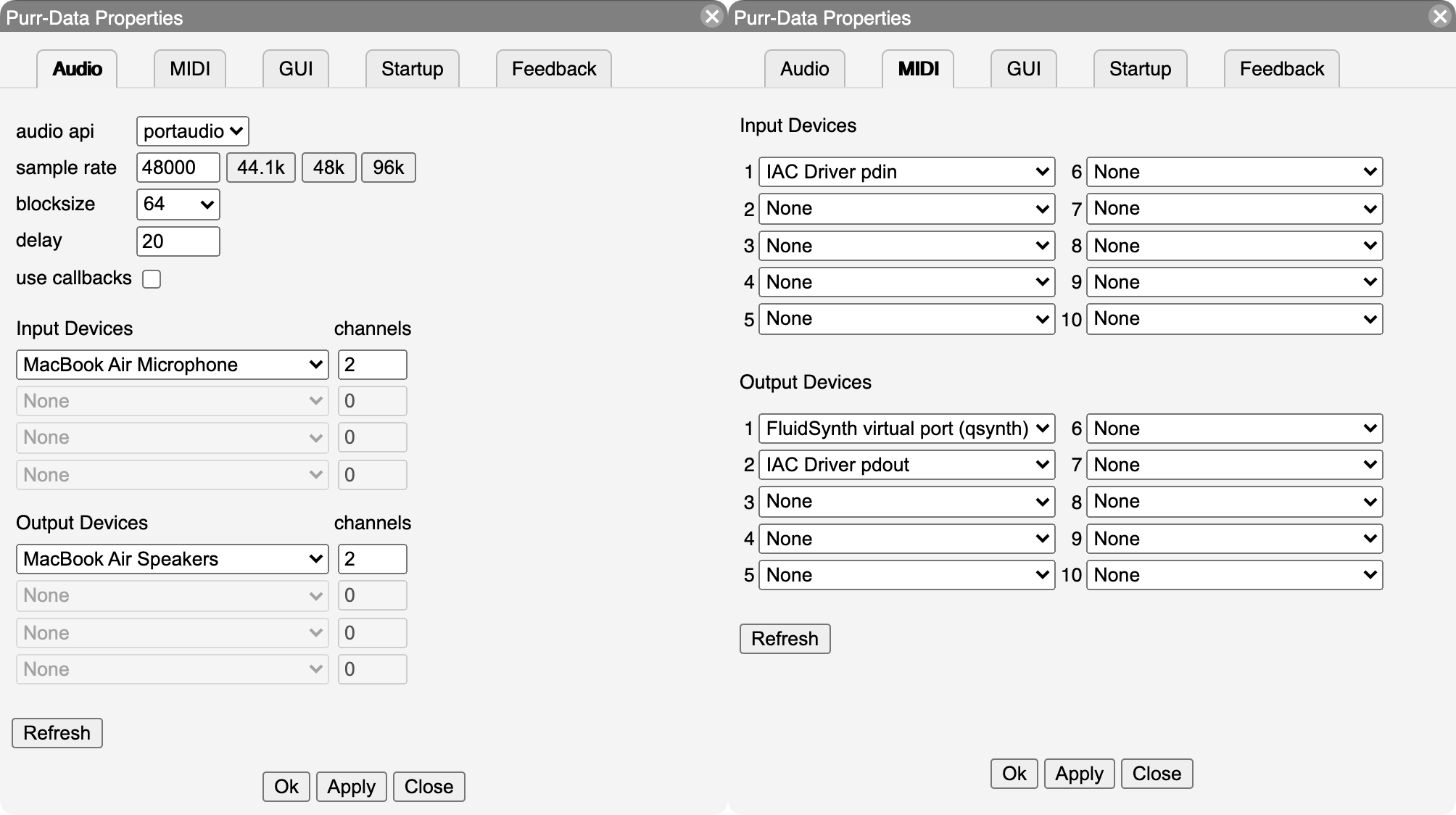
Setup Audio et MIDI sous macOS
La configuration sous Windows fonctionne de manière similaire à celle sous Mac.
Plus d’informations pour les utilisateurs de GNU/Linux peuvent être trouvées dans le Wiki de Purr Data.
Un écueil du moteur Pd (utilisé par Purr Data) est qu’il ne réanalyse pas les périphériques si vous connectez un nouvel équipement Audio ou MIDI externe alors que Purr Data est déjà en cours d’exécution. Vous devez donc relancer le programme pour faire apparaître les nouveaux appareils dans Préférences. Dans le cas du MIDI, il est facile de contourner cette limitation en utilisant des périphériques MIDI virtuels, ce que fait ALSA MIDI par défaut. Sur Mac, vous utiliserez les périphériques IAC, sur Windows un pilote de bouclage MIDI tel que loopMIDI à cet effet. Vous les connectez ensuite au matériel MIDI à l’aide d’un programme de patchbay distinct. Une approche similaire est possible avec un logiciel de bouclage Audio tel que JACK Audio Connection Kit.
Interface utilisateur (GUI) et Options de démarrage (Startup Options)
Le thème du GUI peut être sélectionné-changé dans l’onglet GUI (voir capture gauche ci-dessous). Les modifications seront appliquées immédiatement.
Purr Data propose différents thèmes GUI prêts à l’emploi. Notez que les thèmes GUI ne sont en fait que des fichiers CSS dans le répertoire de la bibliothèque de Purr Data, donc si vous êtes familier avec HTML5 et CSS, vous pouvez facilement les modifier ou créer les vôtres.
Dans les versions 2.14.1 et ultérieures de Purr Data, l’option grille de fond en mode édition active la grille en mode édition, qui aide à positionner les objets et vous permet de voir d’un coup d’œil quand le mode édition est actif.
Une autre option utile sur l’onglet GUI est save/load zoom level with patch (enregistrer/charger le niveau de zoom avec le patch). Purr Data peut zoomer n’importe quelle fenêtre de patch sur 16 niveaux différents, et cette option, lorsqu’elle est activée, vous permet de stocker le niveau de zoom actuel lorsqu’un patch est enregistré, puis de restaurer ultérieurement et automatiquement le niveau de zoom lorsque le patch est rechargé.
Les autres options de l’onglet GUI sont liées au navigateur d’aide, nous en discuterons dans la section Configuration du navigateur d’aide (Configuring The Help Browser) ci-dessous.
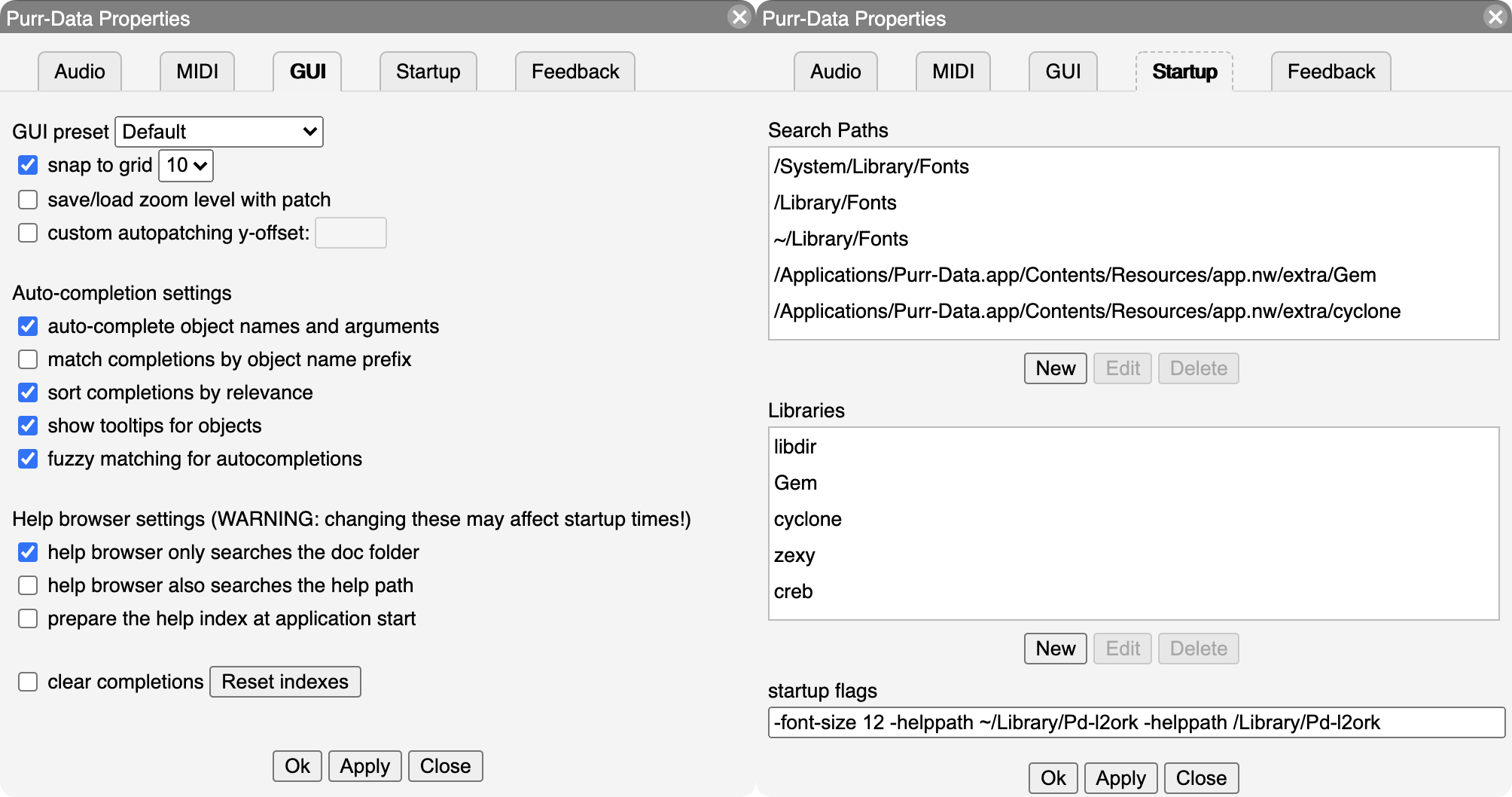
GUI and Startup Options sous macOS
Le dernier onglet de la boîte de dialogue Preferences est l’onglet Startup (Démarrage) (voir capture droite ci-dessus), qui vous permet de modifier les listes des chemins de bibliothèques et les bibliothèques chargées au démarrage, ainsi que les options supplémentaires avec lesquelles le programme doit être appelé. Par défaut, Purr Data charge la plupart des bibliothèques externes regroupées au démarrage et ajoute les répertoires correspondants à son chemin de recherche de bibliothèques. Si vous n’avez pas besoin de tout cela, vous pouvez supprimer des chemins de recherche et/ou des bibliothèques individuels à l’aide des listes Search Paths (Chemins de recherche) et Libraries (Bibliothèques) de l’onglet Startup (Démarrage). Cliquez simplement sur un chemin de recherche ou une bibliothèque puis cliquez sur le bouton Delete (Supprimer). Il est également possible de sélectionner un élément et d’ajouter vos propres chemins de recherche et bibliothèques externes (externals) avec le bouton New (Nouveau), ou de modifier une entrée existante avec le bouton Edit (Modifier).
Liste des bibliothèques externes d’objets (~ 30) actuellement installées par défaut dans Purr Data :
- Creb — Collection of general purpose externals
- Cxc — Library of objects for random numbers and system tools
- Cyclone — Set of objects cloned from Max/MSP
- Disis — Digital Interactive Sound & Intermedia Studio
- Ekext — Objects for music information retrieval and polyphony control
- Ext13 — Collection of file and message objects
- Freeverb~ — Studio-quality Schroeder/Moorer reverberation object
- GEM — Graphics Environment for Multimedia
- Ggee — Library of GUI controls, filters, and more
- Hcs — Library of experiments in UNIX, the Pd GUI, and more
- IEMlib — Collection of general purpose objects and filters developed at IEM
- Jmmmp — Set of several base utilities that make coding a bit easier working in conjunction with Cyclone, Ext13, Ggee, IEMlib, IEMmatrix and Zexy
- LyonPotpourri — Collection of DSP objects
- Mapping — Library for creatively mapping data
- Markex — Library of miscelaneous objects from Mark Danks
- Maxlib — Library for analysing musical performance
- Memento — …
- Mjlib — Library of objects for composing music
- Motex — Collection of objects that mostly provide some math functions
- Oscx — Basic old library for Open Sound Control (OSC) communications
- Pan — Library of stereo panning algorithms
- Pddp — Support library for the Pure Data Documentation Project
- PdLua — Extension for embedding LUA scripting language
- Pdogg — Audio collection of ogg/vorbis objects
- PixelTango — Set of abstractions and externals for GEM
- RRADical — Reusable & Rapid Audio Development to create a patches collection making Pd easier and faster to use
- Sigpack — Signal processing effects library
- Smlib — Signal processing library for Mapping
- Unauthorized — Collection of GUI objects and a couple of Audio utilities
- Vbap — Library for Vector Base Amplitude Panning spatialization
- Zexy — The Swiss Army Knife for Pd
Au bas de l’onglet Startup, il y a un champ startup flags (drapeaux de démarrage) qui vous permet de spécifier les options supplémentaires avec lesquelles le programme doit être appelé. Ceci est couramment utilisé pour ajouter des options comme -legacy (qui impose la compatibilité des bogues avec Pd Vanilla) ainsi que les options -path et -lib qui fournissent une autre façon d’ajouter des chemins de recherche et des bibliothèques externes. Par exemple, pour ajouter les extensions Pure et Faust de JGU (Johannes Gutenberg University) aux bibliothèques de démarrage, le champ Startup Flags peut contenir quelque chose comme : -lib pure -lib faust/pdfaust.
Toutes les options de démarrage souhaitées peuvent être définies de cette façon, c’est-à-dire tout ce que Pd Vanilla accepte généralement sur la ligne de commande. Cependant, notez que les indicateurs de démarrage nécessitent que vous relanciez Purr Data pour que les options prennent effet (il en va de même si vous modifiez la liste des bibliothèques de démarrage). De plus, bien que la définition de chemins et de bibliothèques via les indicateurs de démarrage soit souvent pratique, il y a certains inconvénients à avoir ces options à deux endroits différents, voir les Sticky preferences (Préférences collantes *mettre un lien ici*) dans la section Tips and Tricks (Trucs et astuces *mettre un lien ici*) ci-dessous.
Comme pour les autres options de configuration, n’oubliez pas de cliquer sur le bouton OK pour enregistrer vos modifications dans la mémoire permanente. Cela fermera également la boîte de dialogue Preferences.
Enfin, notez que si votre configuration est sérieusement compromise, il existe des moyens de réinitialiser Purr Data à sa configuration par défaut, voir Resetting the preferences (Réinitialisation des préférences) dans la section Tips and Tricks (Trucs et astuces) *ajouter liens*.
♦ Obtenir de l’Aide
Le meilleur moyen pour les nouveaux utilisateurs d’apprendre à utiliser Purr Data, et Pd Vanilla en général, est son excellent système d’aide intégré. C’est vraiment l’une des caractéristiques principales des programmes Purr/Pure Data, quelle que soit la saveur que vous utilisez. Le système d’aide de Purr Data propose des centaines de patches d’aide couvrant de nombreux domaines différents, et ceux-ci ne sont pas seulement de la documentation, ce sont de véritables et fonctionnels patches (modules .pd) que vous pouvez exécuter pour les essayer, puis copier et coller les parties pertinentes directement dans vos propres patches.
À gauche : About Pd-l2ork / Purr Data — Au milieu : Help Browser — À droite : Quick Reference liste les objets directement intégrés dans Purr Data
Purr Data a.k.a. Pd-l2ork v.2 under GNU/Linux — An improved version of Pure Data (Vanilla)
Il convient de noter ici que Purr Data, comme Pd-l2ork, continuent de s’appuyer sur les efforts de documentation de Pd-extended. Cela comprend plus de 200 nouveaux et mis à jour fichiers d’aide, y compris la documentation de la bibliothèque Cyclone. Tous les nouveaux fichiers d’aide fournissent des méta-informations de support contenues dans le sous-patch META (qui sont nécessaires, en particulier, pour permettre des recherches par mot-clé), en suivant les normes établies par le Pure Data Documentation Project (PDDP). Cependant, il s’agit d’un effort continu et tous les patches d’aide n’ont pas encore été convertis.
Bien que la quantité de patches d’aide puisse être écrasante au début, certaines sections de la documentation sont organisées en didacticiels, de sorte que vous puissiez les parcourir étape par étape.
Cela comprend tous les patches d’aide qui accompagnent le livre de référence complet de Miller Puckette Theory and Techniques of Electronic Music (PDF & HTML / EN – 2007), qui sont toujours le meilleur moyen de se familiariser avec Pd Vanilla et ses variantes. Si vous êtes nouveau sur Pd, nous vous recommandons de parcourir au moins les sections ‘Control Tutorials’ et ‘Audio Tutorials’, et d’essayer vraiment de comprendre ce qui se passe dans ces patches. Avec un logiciel complexe comme Pd, il est trop facile d’être victime de mauvaises habitudes si vous copiez simplement à l’aveugle des parties de patches d’autres personnes. Vous devriez résister à cette tentation, au moins jusqu’à ce que vous ayez acquis une solide base, et ces deux sections vous la fourniront.
Vous pouvez aussi consulter ces deux livres mises gracieusement à la disposition de la communauté sous format PDF : Pure Data – Floss Manuals (FR – 2017) et Bang – Pure Data (EN – 2006).
Le point d’entrée central de Purr Data dans le système d’aide est son navigateur d’aide, décrit ci-dessous. De plus, comme avec les autres versions de Pd, il est également possible d’ouvrir le patch d’aide pour un objet en cliquant simplement dessus avec le bouton droit de la souris dans un patch et en choisissant l’élément de menu contextuel Aide.
Le Navigateur d’Aide
L’utilisation dans le Menu principal de l’entrée Help / Help Browser (raccourcis clavier : Ctrl + B ou Cmd + B sur Mac) lance le navigateur d’aide intégré de Purr Data. Il est en fait assez facile à utiliser (voir les captures ci-dessous) mais il offre beaucoup de fonctionnalités sous le capot. Vous pouvez rechercher des noms d’objets ou des mots-clés en les tapant dans le champ de saisie de recherche en haut du navigateur, ou vous pouvez parcourir les sections de documentation disponibles dans l’écran d’accueil du navigateur, qui est ce qui s’affiche initialement sous l’entrée de recherche, juste en cliquant sur l’un des titres de section.
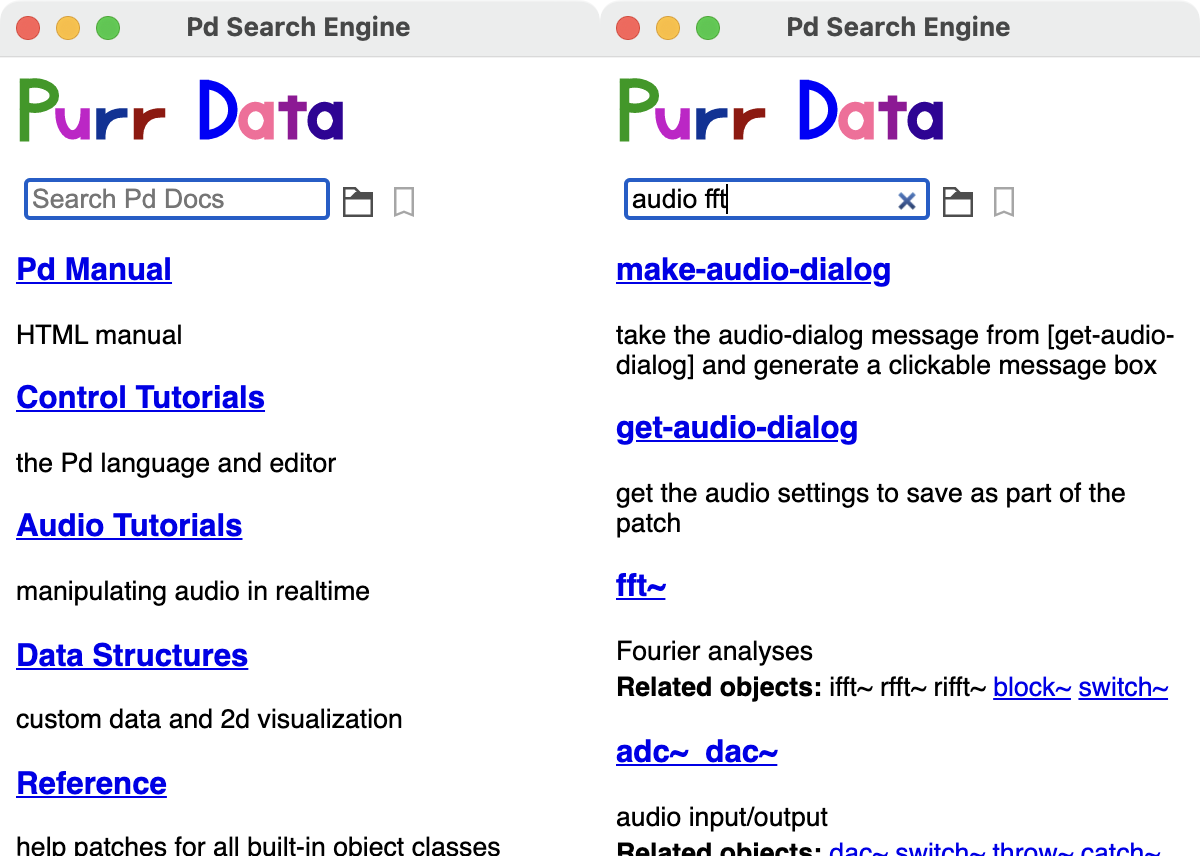
Help browser sous macOS
Dans la capture d’écran ci-dessus à droite vous pouvez voir comment l’affichage change après avoir entré des termes de recherche comme audio devices et appuyé sur Entrée. Comme indiqué, vous pouvez saisir plusieurs termes de recherche et ils seront tous recherchés en une seule fois (ce qui correspond à chacun des termes de recherche donnés, c’est-à-dire que tous les patches seront affichés pour lesquels au moins un des termes de recherche correspond). Les patches d’aide trouvés seront affichés dans la liste (avec une brève description des patches si disponibles). Vous pouvez ensuite cliquer sur l’un des patches pour l’ouvrir dans une fenêtre de canevas. En cliquant sur le symbole x dans le champ de recherche, vous revenez à l’écran d’accueil (réinitialisation des recherches).
Notez que pour garder les choses simples et ne pas submerger les utilisateurs novices avec trop d’informations, la fonction de recherche ne couvre que la documentation ‘officielle’ (la doc/ hiérarchie) par défaut. Il existe des moyens de modifier la portée de la recherche par mot-clé dans les préférences de l’interface graphique, voir Configuring the Help Browser ci-dessous. Mais dans tous les cas, il est également possible d’explorer tous les autres patches d’aide disponibles dans l’extra/ hierarchy (qui contient toutes les abstractions et bibliothèques externes – externals), en utilisant la petite icône de dossier à droite du champ de recherche. Cela ouvrira un navigateur de fichiers (initialement sur le dossier doc/) qui peut ensuite être utilisé pour parcourir tous les patches d’aide disponibles. Lorsque vous recherchez des patches d’aide dans la hiérarchie extra/, qui est un frère de doc/, accédez simplement à ce répertoire dans le navigateur de fichiers et cliquez sur l’un de ses sous-répertoires contenant les différentes abstractions et externals. Double-cliquer sur un patch d’aide ouvrira le patch dans sa propre fenêtre, puis affichera également le répertoire correspondant dans le navigateur d’aide, afin que les patches d’aide supplémentaires du même dossier soient accessibles sans plus attendre.
Si vous connaissez déjà le nom d’un sous-répertoire avec des patches d’aide intéressants, vous pouvez également taper son nom dans le champ de recherche (y compris avec le préfixe doc/ ou extra/) pour afficher le dossier correspondant dans le navigateur d’aide. Par exemple, taper extra/mrpeach validé par Entrée fournit un moyen rapide d’accéder aux patches d’aide pour les externals mrpeach. Si vous avez des correctifs d’aide qui sont en dehors du répertoire du programme (par exemple, quelque part dans votre répertoire personnel), vous pouvez également taper un nom de répertoire absolu pour y accéder.
Notez que dans tous les cas, vous pouvez toujours revenir à l’écran d’accueil du navigateur d’aide en cliquant sur le petit symbole x dans le champ de recherche (ou en appuyant simplement sur la touche Échap avec le curseur situé dans ce champ).
Bookmarks / Marque-pages de l’Aide
Depuis Purr Data 2.14.1, le navigateur d’aide offre une fonction de favoris-signets simple mais efficace qui vous permet d’ajouter des répertoires avec des patches Pd à l’écran d’accueil du navigateur, où ils seront affichés dans leur propre section Bookmarks (Favoris) en bas de la page d’accueil.
Pour ajouter un nouveau favori-signet, accédez d’abord au répertoire sur votre système que vous souhaitez ajouter (en utilisant, par exemple, le navigateur de fichiers, ou en tapant simplement le nom du répertoire dans l’entrée de recherche), puis cliquez la petite icône de signet (à droite de l’icône du navigateur de fichiers). Une petite croix rouge sur l’icône de signet indiquera que le répertoire a été marqué et que le fait d’appuyer à nouveau sur l’icône de signet supprimera ce signet (voir la capture d’écran ci-dessous à gauche). Les raccourcis clavier Ctrl + D (Ajouter un signet) et Ctrl + Maj + D (Supprimer le signet) peuvent également être utilisés.
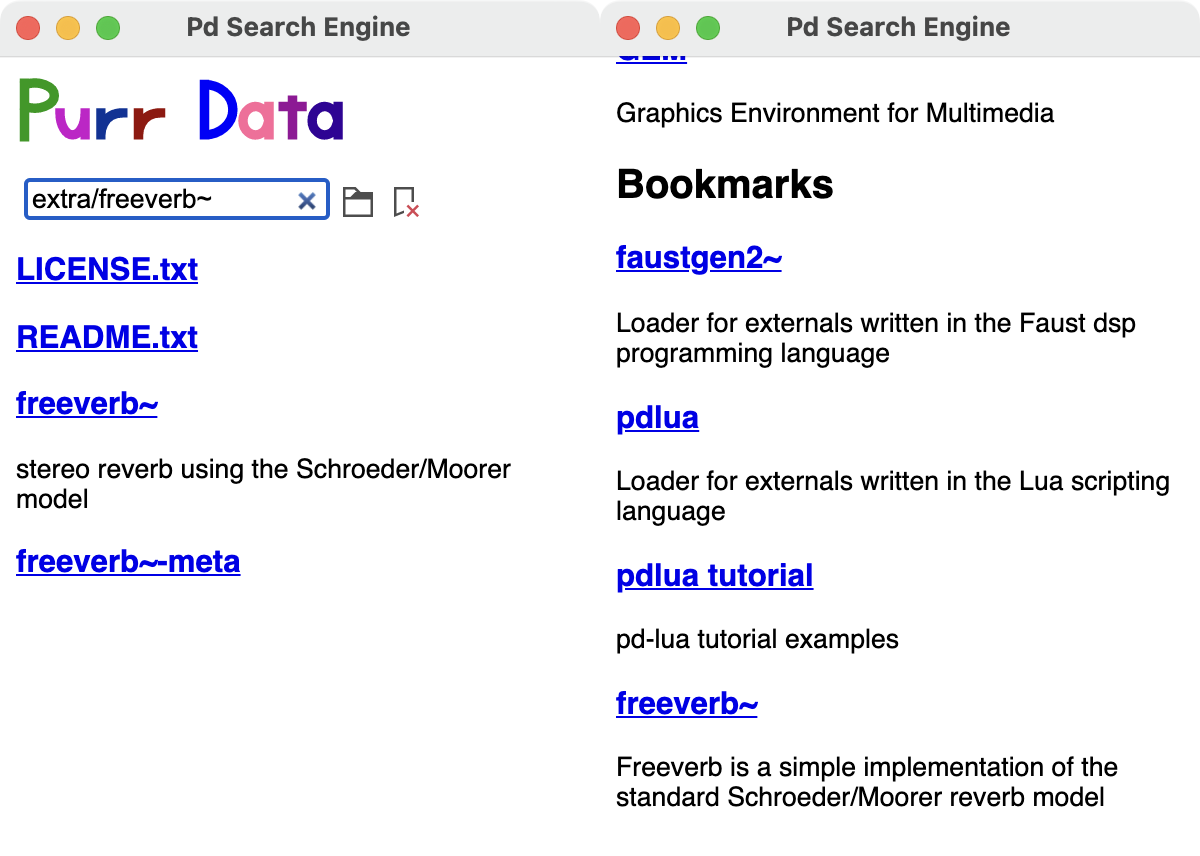
Ajouter des favoris-signets
Vous pouvez ensuite appuyer sur Échap pour revenir à l’écran d’accueil, où le répertoire marqué sera désormais affiché dans la section Bookmarks en bas de la fenêtre du navigateur (vous devrez probablement faire défiler vers le bas pour le voir). Notez que l’en-tête de la section Bookmarks ne sera affichée que s’il y a des signets à afficher (voir la capture d »écran ci-dessus à droite).
Les favoris-signets sont stockés au format JSON dans le répertoire de configuration de l’utilisateur (qui se trouve dans le répertoire personnel, c’est-à-dire ~/.purr-data sous GNU/Linux et Mac, et /Users/username/AppData/Roaming/Purr-Data sous Windows). Ce fichier est dans un format lisible par l’utilisateur et facilement modifiable. Donc si nécessaire, vous pouvez réorganiser vos signets à votre guise en éditant ce fichier dans votre éditeur de texte préféré.
Configuration du Navigateur d’Aide
L’onglet GUI dans la boîte de dialogue des Preferences (cf. GUI et Startup Options) propose quelques options pour configurer l’étendue de la recherche par mot-clé. Notez que pour effectuer des recherches par mots-clés, le navigateur d’aide doit d’abord construire un index de tous les patches d’aide et de leurs mots-clés. Cela se fait soit à la volée, lorsque le navigateur d’aide est ouvert pour la première fois pendant une session Purr Data (c’est la valeur par défaut), ou lorsque l’application est lancée (il y a une case à cocher qui vous permet d’activer cela). À partir de Purr Data 2.14.1, l’index de l’aide est mis en cache dans le répertoire de configuration de l’utilisateur (voir Bookmarks ci-dessus) et n’est reconstruit à partir de zéro que lorsque cela est nécessaire (c’est-à-dire si le contenu des répertoires indexés change).
Une fois que le navigateur d’aide a été lancé pour la première fois et que l’index a été construit et mis en cache, il apparaîtra toujours rapidement lors des appels suivants. Mais en fonction du nombre de patches que vous indexez, la création de l’index au premier lancement peut prendre un certain temps (de moins d’une seconde à plusieurs secondes sur du matériel moderne), donc la modification de ces options aura un impact sur le temps d’indexation. Cela ne devrait pas poser beaucoup de problème car l’indexation ne devra être effectuée qu’une seule fois (après une nouvelle installation ou une mise à niveau de Purr Data). Mais si vous utilisez rarement le navigateur d’aide, vous voudrez peut-être vous assurer que l’option ‘prepare the help index at application start’ (préparer l’index de l’aide au démarrage de l’application) n’est pas cochée (ce qui est la valeur par défaut). De plus, il existe deux options qui vous permettent de modifier la portée des patches indexés (la modification de ces options prendra effet dès que vous relancerez le navigateur d’aide et déclenchera la création d’un nouveau fichier d’index) :
Deux options vous permettent de modifier la portée des patches indexés :
- Si help browser only searches the doc folder (le navigateur d’aide recherche uniquement dans le dossier doc) est coché (ce qui est la valeur par défaut), les recherches par mot-clé sont limitées à la hiérarchie doc/. C’est l’option la plus rapide et elle sera suffisante au moins pour les utilisateurs novices car elle couvre toute la documentation officielle fournie avec Purr Data. Cependant, si vous êtes un utilisateur expérimenté et que vous utilisez fréquemment des bibliothèques tiers externes présentes dans la hiérarchie extra/, vous pouvez décocher cette option pour que tous les sous-répertoires restants du répertoire de la bibliothèque pd-l2ork soient également indexés (notez que cela peut ralentir considérablement l’indexation).
- L’option help browser also searches the help path (le navigateur d’aide recherche également dans le chemin d’aide), lorsqu’elle est cochée, vous permet d’adapter la recherche par mot-clés aux éléments externes avec lesquels vous travaillez, afin que vous ne soyez pas submergé de correspondances de mots-clés provenant d’éléments externes que vous n’utilisez jamais. Ces éléments externes peuvent se trouver n’importe où, y compris dans la hiérarchie extra/, mais notez que si vous avez déjà décoché l’option ‘help browser only searches the doc folder’ (le navigateur d’aide ne recherche que dans le dossier doc), il n’est pas nécessaire d’ajouter explicitement des sous-répertoires extra/. Dans les deux cas, les répertoires à rechercher avec cette option sont définis à l’aide du chemin d’aide de Purr Data (les avoir dans le chemin de recherche de la bibliothèque ne suffit pas). Pour ce faire, utilisez l’option -helppath de Purr Data qui peut être ajoutée au champ ‘startup flags’ au bas de l’onglet Startup. Par exemple, sous GNU/Linux, vous pouvez ajouter quelque chose comme -helppath ~/pd-l2ork-externals (ce répertoire est souvent utilisé sous GNU/Linux pour les collections personnelles et personnalisées de bibliothèques externes).
Mise en garde : Encore une fois, sachez que la modification de ces options, puis l’installation de bibliothèques externes avec des milliards de patches dans la hiérarchie extra/ et/ou dans votre chemin d’aide personnel peuvent avoir un impact très négatif sur les premiers temps de lancement, car tous ces patches devront être analysés lors de la création de l’index.
♦ Friandises Pd-L2Ork et Purr Data
Par rapport à Pd Vanilla, Pd-l2ork et Purr Data fournissent un ensemble complet de fonctionnalités nouvelles et améliorées, beaucoup trop pour même les mentionner toutes. Nous renvoyons donc le lecteur intéressé au document PdCon 2016 Paper (en anglais) pour plus de détails. Le document couvre également l’histoire et la motivation du projet Pd-l2ork.
L’une des avancées majeures de Pd-l2ork, qui n’a été portée que récemment sur Pd Vanilla, est sa capacité d’annulation infinie, qui permet d’annuler facilement les modifications accidentelles et/ou volontaires sans avoir à se soucier de prendre des instantanés des patches pendant qu’ils sont en cours de développement. Une autre modification utile qui mérite également d’être mentionnée ici est l’option Arranger (agencement amélioré) dans le menu Édition, qui aligne d’abord les objets, puis les espace à égale distance. La plupart des autres nouvelles fonctionnalités sont simplement des améliorations de l’interface graphique et de l’utilisabilité qui deviennent rapidement une seconde nature pour l’utilisateur, telles que les améliorations graphiques, la possibilité de redimensionner les éléments de l’interface graphique IEM et les zones GOP (Graph-on-Parent) à l’aide de la souris, ainsi que les raccourcis clavier pour les objets [number] et [number2].
D’autres fonctionnalités seront plus utiles pour les utilisateurs avancés, comme les capacités de réflexion (voir les patches d’aide [pdinfo], [canvasinfo], [classinfo] et [objectinfo]) et les nouveaux éléments SVG pour les visualisations de structure de données. Ces derniers ont été considérablement améliorés dans Purr Data, voir la section ‘Pd-L2Ork Data Structures’ (Structures de données Pd-L2Ork) dans le navigateur d’aide. Ils permettent également de créer vos propres éléments GUI personnalisés en ‘pur’ Purr Data, sans avoir à apprendre un ‘vrai’ langage (textuel) de programmation.
Connexions intelligentes / Intelligent Patching
Un autre gros gain de temps pour l’utilisateur est la fonction Intelligent Patching (connexions intelligentes) de Pd-l2ork, qui vous permet de sélectionner deux ou plusieurs objets afin de connecter plusieurs sorties et entrées en une seule fois.
Les connexions intelligentes offrent un certain nombre de modes différents :
- Si vous sélectionnez exactement, disons, deux objets A et B, puis connectez l’une des sorties de A à l’une des entrées de B, puis à partir de la paire initiale sortie-entrée, les sorties restantes de A seront connectées aux entrées correspondantes de B.
- Si vous sélectionnez, disons, deux (ou plus) objets B et C, puis connectez la sortie d’un troisième objet A non sélectionné à une entrée de B, la connexion correspondante de A à C se fera automatiquement. Inversement, vous pouvez également connecter une sortie de B à une entrée de A pour que la connexion C-A correspondante soit établie pour vous.
- Si vous sélectionnez, disons, trois (ou plus) objets A, B et C, où A a deux sorties ou plus, puis connectez une sortie de A à une entrée de B, la prochaine sortie de A sera connectée à la sortie correspondante entrée de C. Inversement, vous pouvez également connecter une sortie de B à une entrée de A, et avoir la sortie correspondante de C connectée à l’entrée suivante de A. Cela fonctionne pour un nombre arbitraire d’objets source ou cible, compte tenu des ‘autres’ objets dans l’ordre ‘de-gauche-à-droite’ puis ‘de-haut-en-bas’.
Cette opération fonctionne mieux si les ‘autres’ objets n’ont qu’une seule sortie ou entrée, car cela rend le résultat sans ambiguïté. Sinon, Purr Data préférera souvent créer des connexions sortantes, auquel cas vous devrez maintenir la touche Ctrl enfoncée pour appliquer les connexions entrantes. - Enfin, appuyez sur la touche Maj tout en faisant des connexions vous permettra de faire plusieurs connexions à partir de la même sortie en une seule fois.
Purr Data possède un patch d’aide pour cette fonction incroyablement utile, que j’ai également fourni avec ce document dans le patch intelligent-patching.pd pour votre lecture. Dans les commentaires, le patch comprend également des explications détaillées sur tous les différents modes de patching intelligents, et vous pouvez trouver des sous-patchs avec des exercices dans la marge du patch principal.
Fonctionnalités de Sous-patch et d’Abstraction
Un ajout majeur et récent à Purr Data sont les fonctionnalités étendues de création et de sauvegarde de sous-patchs et d’abstractions, qui ont été fournies par Guillem Bartrina pendant le Google Summer of Code 2020.
- Une nouvelle option Encapsuler dans le menu Édition vous permet de transformer une collection d’objets sélectionnés en un sous-patch unique correspondant de manière entièrement automatique. Cela rend enfin la création de pièces uniques à partir de parties de vos patches une opération très rapide et facile.
- Vous pouvez également transformer un sous-patch unique existant en une abstraction simplement en cliquant avec le bouton droit sur l’objet et en choisissant la nouvelle option Enregistrer sous dans le menu contextuel. Cela vous donnera également la possibilité de remplacer le sous-patch existant, ainsi que toutes ses autres instances par l’abstraction nouvellement créée.
- Il existe un nouvel objet [ab], à appeler en tant que [ab name args…], qui vous permet de créer des abstractions privées. Celles-ci sont intégrées dans leur patch parent comme un sous-patch unique [pd name], mais se comportent autrement comme de vraies abstractions en ce sens qu’elles ont leur propre $0 et peuvent aussi avoir des arguments. Elles fonctionnent donc exactement comme les anciennes abstractions, mais deviennent une partie de votre patch principal, un peu comme les sous-routines d’un programme C. Cela rend l’expédition d’un patch beaucoup plus pratique, car vous n’avez plus à envoyer tout un tas de fichiers d’abstraction avec lui.
- L’objet [ab] est accompagné d’un certain nombre d’objets supplémentaires ([abinfo], [abdefs], [abclone]) qui vous permettent d’inspecter et de cloner des abstractions privées. Il existe également une boîte de dialogue Abstractions accessible via le menu Fenêtre. Cela vous donnera un aperçu rapide des abstractions privées contenues dans un patch. En outre, il vous montrera des abstractions privées qui ne sont pas actuellement utilisées (c’est-à-dire qui n’ont aucune instance), afin que vous puissiez les sélectionner, puis les supprimer si elles ne sont plus nécessaires.
♦ Purr Data et Pd-Lua
Depuis la version 2.5, Purr Data inclut la dernière version de l’excellente extension Pd-Lua de Claude Heiland-Allen pour intégrer le langage de script Lua dans Purr Data. Cela vous offre un moyen simple (beaucoup plus facile que l’interface C native de Pure/Purr Data) d’écrire vos propres objets Purr Data personnalisés s’ils nécessitent l’utilisation d’un véritable langage de programmation offrant des boucles, des fonctions et des structures de données complexes.
Lua est parfaitement adapté à cet effet, car il est léger et facilement intégrable par conception. Il est également petit et facile à apprendre, mais très performant, offrant une gamme complète d’éléments de langage de programmation impératifs, orientés objet et fonctionnels. Comme Purr Data, Lua est un langage interprété comportant un typage dynamique, ce qui rend l’interfaçage assez facile entre Purr Data et Lua.
Pd-Lua nécessite Lua 5.2, 5.3 ou 5.4, qui devraient être facilement disponibles dans toutes les bonnes distributions GNU/Linux (sur macOS et Windows, la bibliothèque Lua requise est incluse dans le programme d’installation de Purr Data). Un didacticiel A Quick Introduction to Pd-Lua (en anglais) est disponible pour vous aider à démarrer et une collection assez complète d’exemples se trouve dans le dossier extra/pdlua/examples de Purr Data.
♦ Trucs et Astuces
Nous concluons cette introduction avec un petit jeu de trucs et astuces utiles. Si vous ne trouvez pas de réponse à vos questions ici, veuillez les publier sur la liste de diffusion DISIS Pd-l2ork.
Mode Édition et Mode Exécution Temporaire
Le Mode Exécution Temporaire (temporary run mode) est une fonctionnalité présente dans différentes versions de Pd qui vous permet de passer rapidement au mode d’exécution (où vous pouvez utiliser les éléments de l’interface graphique dans un patch) à partir du mode d’édition (où vous pouvez éditer le patch). Dans Pd Vanilla, ainsi que dans la plupart des autres saveurs de Pd, cela est activé en appuyant et en maintenant la touche de modification Ctrl (ou la touche Cmd sur Mac).
Dans Purr Data, le modificateur a été remplacé par la touche Alt à partir de la version 2.14.1, car la liaison de la touche Ctrl provoquait des conflits avec les raccourcis clavier du menu. Cela a entraîné des régressions assez sérieuses dans l’interface graphique, telles que certains raccourcis clavier du menu ne fonctionnant plus comme prévu ou interférant avec le Mode Édition.
En plus de devoir s’habituer à ce nouveau raccourci de clavier, cela implique également un problème potentiel pour les utilisateurs de GNU/Linux, car de nombreux environnements de bureau Linux utilisent Alt-clic pour lancer une action de déplacement de fenêtre, ce qui interférera avec le mode d’exécution temporaire. Vous rencontrez ce problème si vous essayez d’utiliser des éléments d’interface graphique avec une action de Clic-Glisser tout en maintenant la touche Alt enfoncée, pour constater que cela déplace la fenêtre du patch à la place. Pour que le mode d’exécution temporaire fonctionne à nouveau, assurez-vous de relier l’action de déplacement des fenêtres à une touche de modification et/ou à un bouton de la souris différents, tels que Meta+Clic ou Alt+Clic-du-milieu qui sont rarement utilisés par les gestionnaires de fenêtres, au moins pas pour les actions importantes.
La version 2.14.1 de Purr Data a également introduit la grille du mode Édition comme un meilleur moyen d’indiquer que le mode d’édition est actif, tout en étant également utile comme aide au positionnement des objets. (Veuillez noter qu’il n’y a pas encore d’option ‘snap-to-grid’, mais cela pourrait être ajoutée dans une future version.) Cette grille est activée par défaut, mais peut être désactivée dans l’onglet GUI des Préférences si vous n’en avez pas besoin.
Installer Pd-L2Ork classique aux côtés de Purr Data
Sous GNU/Linux, il existe certaines situations où vous souhaiterez peut-être exécuter à la fois Pd-L2Ork classique et Purr Data sur le même système. Cela peut être utile, par exemple, si vous avez besoin d’une fonctionnalité de Pd-l2ork comme son mode K-12 (12 premières années d’enseignement maternelle-primaire-collège aux États-Unis) qui n’a pas encore été porté sur Purr Data. Pour ce faire, vous avez besoin de l’un des packages JGU (Johannes Gutenberg University) de Purr Data (voir Obtenir Purr Data). Ceux-ci seront installés dans un répertoire séparé (normalement /opt/purr-data) afin que les chemins d’accès des binaires et des bibliothèques dans le paquet ne soient pas en conflit avec ceux d’une installation classique de Pd-l2ork sous /usr. Les icônes du bureau seront également nommées différemment, et un lien symbolique nommé purr-data sera créé dans le répertoire /usr/bin. Le lien pointe vers /opt/purr-data/bin/pd-l2ork et vous permet d’exécuter Purr Data à partir de la ligne de commande sans avoir à spécifier le chemin d’accès complet à l’exécutable. Enfin et surtout, les packages JGU ont également été corrigés de sorte qu’ils utilisent un répertoire de configuration .purr-data distinct dans votre répertoire personnel au lieu du dossier .pd-l2ork de Pd-l2ork, afin que les deux programmes puissent coexister avec bonheur.
Installer des bibliothèques externes (externals)
Purr Data regroupe déjà de nombreux (~ 30) sinon la plupart des bibliothèques tiers externes couramment utilisées par les utilisateurs de Pd. Pour en ajouter encore plus, il existe des répertoires spéciaux dans lesquels vous pouvez installer les éléments externes afin que Purr Data puisse les trouver. C’est fondamentalement la même chose qu’avec Pd-extended, mais les répertoires sont nommés différemment afin que vous puissiez garder si nécessaire les bibliothèques externes de Purr Data distinctes de celles de Pd Vanilla / Pd-extended. Il y a toujours un emplacement pour l’ensemble du système et un autre pour l’installation personnelle.
Les emplacements et noms précis de ces répertoires dépendent de votre plateforme :
- GNU/Linux : /usr/lib/pd-l2ork-externals pour l’ensemble du système, ~/pd-l2ork-externals pour une installation personnelle
- Mac : /Library/Pd-l2ork pour l’ensemble du système, ~/Library/Pd-l2ork pour une installation personnelle
- Windows : %ProgramFiles%\Common Files\Pd-l2ork pour l’ensemble du système, %UserProfile%\Application Data\Pd-l2ork pour une installation personnelle
Pour les bibliothèques externes simples, il suffit généralement de les copier dans l’un de ces dossiers, puis de relancer Purr Data. Les bibliothèques externes contenant une collection de différents externals, d’autre part, nécessitent généralement que vous chargiez également la bibliothèque au démarrage, en utilisant les options de configuration de démarrage disponibles dans les Preferences (voir GUI et Startup Options ci-dessus).
Réinitialisation des Préférences
Il peut arriver aux meilleurs d’entre nous que nous gâchions tellement notre configuration Purr Data qu’elle soit irréparable. Dans un tel cas, vous souhaiterez probablement revenir à la configuration par défaut de Purr Data et recommencer à partir d’une table rase. Malheureusement, la boîte de dialogue des Preferences de Purr Data ne fournit pas (encore) de bouton pour cela, mais il existe des moyens simples pour y parvenir.
Ils dépendent cependant de la plateforme particulière utilisée :
- GNU/Linux : dans un Terminal, tapez rm -rf ~/.pd-l2ork -ou- rm -rf ~/.purr-data lors de l’utilisation des packages JGU.
- Mac : dans un Terminal, tapez rm ~/Library/Preferences/org.puredata.pd-l2ork.plist.
- Windows : lancez le programme regedit (avec toutes les précautions habituelles) et recherchez la clé de registre HKEY_CURRENT_USER\Software\Purr-Data -ou- HKEY_LOCAL_MACHINE\Software\Purr-Data. Supprimez cette clé et toutes ses sous-clés (toujours avec précaution).
Ensuite, relancez simplement Purr Data. Vos Préférences devraient à nouveau être à l’état vierge et tous les chemins de recherche par défaut et les bibliothèques de démarrage seront restaurés. Bien sûr, vous devrez ensuite reconfigurer vos appareils Audio et MIDI selon vos besoins.
Préférences « collantes »
Un écueil avec le système de préférences de Purr Data (qu’il partage avec ses prédécesseurs) est que certaines options dans les indicateurs de démarrage (Startup Flags) peuvent remplacer d’autres modifications effectuées manuellement dans la boîte de dialogue des préférences (Preferences), et sembleront alors « coller » lorsque vous relancerez Purr Data. Par exemple, si une bibliothèque est chargée via l’option -lib dans les indicateurs de démarrage, elle apparaîtra également dans la liste des bibliothèques la prochaine fois que vous exécuterez Purr Data. Mais si vous le supprimez simplement ici, et pas également dans les indicateurs de démarrage, la bibliothèque sera toujours chargée la prochaine fois que vous exécuterez Purr Data. La même mise en garde s’applique si vous avez certaines options pour configurer certains aspects de la configuration Audio et MIDI dans les indicateurs de démarrage, puis reconfigurez vos appareils dans les onglets Audio et MIDI de la boîte de dialogue. Ainsi, si Purr Data semble s’en tenir à une certaine configuration Audio ou MIDI même si vous êtes certain d’avoir défini (et enregistré) une nouvelle configuration, vérifiez bien les indicateurs de démarrage, ils sont presque certainement à blâmer. (Un autre coupable possible sont les fichiers de bureau GNU/Linux, voir ci-dessous.)
Ce comportement irritant est dû à la façon dont Purr data gère les indicateurs de démarrage, en particulier les indicateurs qui peuvent remplacer certains comportements dans d’autres options de configuration. Le moyen le plus simple de se débarrasser de tous ces incidents est de supprimer les options pertinentes dans les indicateurs de démarrage (en cas de doute, supprimez-les toutes afin que le champ des indicateurs de démarrage soit complètement vide) et enregistrez vos options en cliquant sur OK dans la boîte de dialogue des préférences.
Parfois, les options peuvent sembler « coller » même si le champ des indicateurs de démarrage est en fait vide, de sorte que la boîte de dialogue des préférences semble être partiellement dysfonctionnelle. Cela est presque certainement dû à certaines options de démarrage errantes dans les fichiers de bureau de l’application, très probablement sous GNU/Linux (les fichiers de bureau d’origine Pd-l2ork, dont Purr Data a hérité dans la version GNU/Linux, semblent être le principal coupable ici). Supprimez les options incriminées dans les icônes du bureau que vous utilisez pour lancer Purr Data, et cela disparaîtra. (Encore une fois, en cas de doute, supprimez simplement toutes les options supplémentaires du fichier de bureau, de sorte que seul le nom du programme reste; aucune de ces options n’est essentielle pour le bon fonctionnement de Purr Data.)
Purr Data se bloque au démarrage
Pour autant que je sache, cela n’a été signalé que sur macOS jusqu’à présent. Le symptôme est que l’interface graphique se lance, mais se bloque ensuite pendant la séquence de démarrage après avoir imprimé le message incoming connection to GUI (connexion entrante à l’interface graphique) dans la fenêtre de la console. L’interface graphique devient alors totalement insensible, consommant jusqu’à 100% du CPU, et le seul moyen de s’en débarrasser est de tuer le processus (« forcer l’arrêt »).
Les causes exactes sont inconnues pour le moment, mais il semble que ce comportement puisse être provoqué par de mauvaises bibliothèques tiers externes provoquant le blocage ou le blocage du moteur temps réel au démarrage. L’interface graphique attend ensuite la connexion entrante du moteur qui n’est jamais établie, ce qui la fait se bloquer à son tour.
Comme il est impossible de lancer l’interface graphique et de supprimer les éléments externes incriminés dans la boîte de dialogue des préférences dans cette situation plutôt malheureuse, la seule solution connue à ce problème est de réinitialiser la configuration (voir Réinitialisation des préférences ci-dessus *lien ici*). Après quoi Purr Data, espérons-le, se lance sans aucun accroche à nouveau. Si vous vous sentez aventureux, vous pouvez alors commencer à ajouter en local vos bibliothèques externes un par un jusqu’à ce que l’interface graphique se bloque à nouveau, auquel cas vous aurez identifié le coupable, afin de pouvoir le supprimer de votre système.
Purr Data démarre très lentement
Encore une fois, cela semble être un problème spécifique à macOS. Les anciennes versions Mac (antérieures à 2.0) de Purr Data avaient le défaut que les anciens chemins de recherche et les bibliothèques de démarrage des installations précédentes continuaient à s’accumuler dans la configuration jusqu’à ce que le démarrage de Purr Data devienne très lent. Cela a été corrigé dans la version 2.0 (et le temps de démarrage sur Mac a également été généralement amélioré), mais si vous utilisez toujours une ancienne configuration avec version post-2.0, vous pouvez encore voir des restes de ce problème même dans la version 2.0.
Une chose que vous pouvez essayer dans ce cas est de lancer la boîte de dialogue des Préférences, appuyez sur OK, puis quittez et relancez Purr Data. Si cela ne vous aide pas, réinitialisez la configuration comme expliqué sous Resetting the preferences (Réinitialisation des préférences) ci-dessus. Si cela ne vous aide pas non plus, alors vous avez probablement un problème différent que vous devez signaler sur l’Issues tracker (suivi des problèmes) de Purr Data.
Commandes Tcl héritées dans les bibliothèques externes
De temps en temps, vous pouvez rencontrer des avertissements sur les ‘commandes Tcl héritées’ dans la fenêtre de la console de Purr Data qui ressemblent généralement à ceci :
legacy tcl command at 201 of ../shared/hammer/file.c: hammereditor_close .86439b0 0
Dans la plupart des cas, ceux-ci devraient être inoffensifs, mais ils peuvent indiquer un élément manquant de la fonctionnalité de l’interface graphique en raison du code Tcl qui n’a pas encore été porté sur la nouvelle interface graphique NW.js de Purr Data. Dans tous les cas, n’hésitez pas à signaler de tels messages sur l’Issues tracker (suivi des problèmes) de Purr Data, afin que, espérons-le, un membre de l’équipe de développement puisse les examiner. Un rapport de bogue approprié doit au moins inclure le message lui-même et l’objet Purr Data auquel il se rapporte. Si certaines étapes spéciales sont nécessaires pour reproduire le message, vous devez également les signaler. De plus, assurez-vous d’abord que le message spécifique que vous voyez n’a pas déjà été signalé dans l’outil de suivi des problèmes.

Purr Data is a graphical data-flow programming environment which is geared towards real-time interactive computer music and multimedia applications.
À vous maintenant de « jouer » avec Purr Data et ses objets graphiques (internes et externes) pour construire vos projets Audio, MIDI et Multimédia !